DataTable操作性能优化 |
您所在的位置:网站首页 › datatables 查询 › DataTable操作性能优化 |
DataTable操作性能优化
|
一、 DataTable操作中的性能问题 最近的一项工作是关于性能提升方面的。要做的第一个事情是要把很多同类型的DataTable合并到一起,查了很多关于DataTable的相关函数以后,我决定用Merge函数来合并这些DataTable。 DataTable[] srcTables = ... ; foreach( DataTable src in srcTables ){ dest.Merge( src ) ; }
但是测试的结果让我很是失望,性能不是一般的不好。经过调查发现性能的瓶颈在Merge函数这里。后来经过测试,发现如果用下面的代码: DataTable[] srcTables = ... ; foreach( DataTable src in srcTables ){ foreach( DataRow row in src.Rows){ dest.ImportRow( row ) ; } }
结果让人惊奇的是,下面的代面的速度是上面的代码速度的100倍! 还做了一个事情,就是对DataTable进行filter的时候 ,我的一个同事和我说了以下的代码: DataView dv = dt.DefaultView ; dv.RowFilter = filter ; DataTable result = dv.ToTable() ;
上面的代码是能工作的,但是它的性能一点都不好,后来我把上面的代码改成了: DataRow[] rows = dv.Select( filter ) ; foreach( DataRow row in rows ){ result.ImportRow(row) ; } 也有数十倍的性能提高。
二、 DataTable数据检索的性能分析 我们知道在.NET平台上有很多种数据存储,检索解决方案-ADO.NET Entity Framework,ASP.NET Dynamic Data,XML, NHibernate,LINQ to SQL 等等,但是由于一些原因,如平台限制,比如说必须基于.NET Framework2.0及以下平台;遗留的或者第三方数据接口采用的就是DataTable等等,仍然需要使用DataTable作为数据存储结构。另一方面DataTable比较容易使用,一些数据访问的接口可能直接采用了DataTable结构。在使用DataTable进行数据检索的时候,有一些需要注意的地方,这些地方会严重的影响对数据的检索效率。 本人最近工作中需要对大量的DataTable进行拼接。接口的数据是以DataSet然后里面放DataTable的方式提供的,暂不提是否合理,同时进行多个请求的时,服务端会返回一个DataSet,其中包含每个请求的结果DataTable,这些DataTable中有一列相当于”关键字”列。现在需要按照这个关键字,将这些DataTable中的列合并到一个DataTable,然后展现到界面上来。 最开始,我使用的是DataTable的Select方法来循环遍历拼接实现的,发现很慢,于是总结了一下对DataTable进行查询等操作的一些经验,和大家分享。
2.1、场景 为了简化问题,有两张DataTable,名为表A,表B,字段分别为 表A,存储股票的最高价信息 表B存储股票最低价信息 SecurityCode High SecurityCode Low 000001.SZ 20 000001.SZ 18.5 000002.SZ 56 000002.SZ 26
现在需要,将这两张表拼接到一张表中,这张表有三列字段,SecurityCode、High、Low,之前采用的方法是,新建一张含有这三个字段的DataTable 表C,然后复制Security字段,然后遍历另外两张表,对其采用Select方法查找对应的SecurityCode,然后复制给C中对应字段。发现效率很慢,问题出现在Select方法上,于是需要进行优化。
2.2 、DataTable的查询效率 (Select和Find方法) DataTable提供了两个查询数据的接口,DataTable.Select和DataTable.Rows.Find方法。 DataTable的Select方法通过传入一系列条件,然后返回一个DataRow[ ]类型的数据,它需要遍历整个表,然后挨个匹配条件,然后返回所有匹配的值。很显然在策略上,之前的DataTable拼接采用Select方法存在问题,因为我们只需要查找匹配上的一条记录即可。 DataTable.Rows 的Find查找第一个匹配上的唯一一条记录。在指定了主键的基础上,查找会采用二叉树的方式查找,效率高。要创建主键,需要指定DataTable的PrimaryKey字段如下: dtA.PrimaryKey = new DataColumn[] { dtA.Columns["SecurityCode"] };
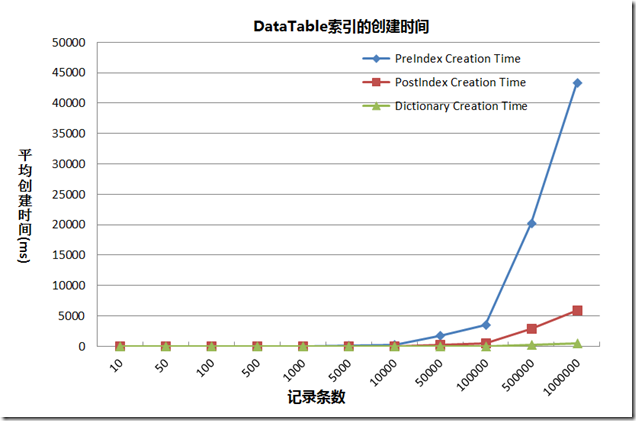
当然,创建主键会增加时间消耗,这也分为在数据填充前创建和数据填充后创建。在数据量大的情况下,创建主键的消耗是需要考虑进去的。下面的图中显示了在填充数据之前创建主键,之后创建主键,以及创建Dictionary所需的时间。可以看到: ArraySize PreIndex Creation Time PostIndex Creation Time Dictionary Creation Time 10 0 0 0 50 0 0 0 100 1 0 0 500 6 1 0 1000 15 2 0 5000 107 16 2 10000 261 42 5 50000 1727 271 31 100000 3525 544 47 500000 20209 2895 240 1000000 43382 5919 517 作图如下: 从上图可以得到: 在填充数据之前创建主键,然后填充数据,比填充数据完之后创建主键消耗的时间要多。这是由于,创建主键后,再向其中添加数据,会导致需要重新生成索引,这和数据库中,不适合在频繁变动的字段上创建主键的原理是一样的。在我的笔记本 (Win7 32bit,CPU T6600 2.0GHZ,RAM 2GB)上,为100万条记录的DataTable创建索引大约需要5秒钟,所以在数据量大的情况下,需要考虑索引的创建时间。 创建DataTable然后创建主键与直接创建和该DataTable相同的Dictionary结构相比,创建Dictionary所需要的时间要少的多,而且几乎不随着记录条数规模的变大而变大。
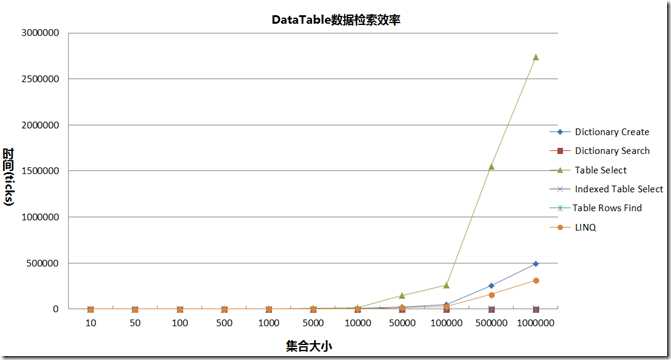
创建完成之后,下面来测试几种情况下的DataTable的检索效率。为此,在建立主键和没有建立索引的条件下,测试了在不同规模下 DataTable.Select, DataTable.Rows.Find 的查询速度,由于在DataTable比较小的时候,时间不能很好的显示,所以测试采用的单位是StopWatch的Tick数。每个方法在数据规模不同的情况下,各执行了10次,然后取平均值,结果如下: ArraySize Dictionary Create Dictionary Search Table Select Indexed Table Select Table Rows Find LINQ 10 13 3 40 25 8 16 50 27 2 69 37 8 27 100 51 3 112 38 9 39 500 210 3 589 51 11 155 1000 461 4 1175 60 14 328 5000 2264 14 8412 85 17 1540 10000 6235 7 16806 99 20 3354 50000 23768 8 150133 138 26 15824 100000 49133 7 259794 147 26 31525 500000 252103 51 1547935 181 30 158317 1000000 494647 9 2736616 209 30 315716 作图如下: 可以看到: 在没有创建主键的条件下,对DataTable执行Select操作时比较低效的。在建立主键之后,仅对主键所在列执行Select操作,速度提高了很多,这种差距在数据量大的情况下尤其明显,在集合大小规模为1000时,该差异达到了近20倍。 LINQ对DataTable的查询效率比DataTale.Select方法要高,但是仍然比DataTable.Rows.Find方法效率要低。 在对主键进行唯一性查找时,我们应该使用DataTable.Rows.Find操作,在DataTable建立主键,并且仅对主键进行操作的情况下,Find方法会比Select方法快3-6倍,这可能是由于Select方法需要对里面的过滤字符串进行解析及判断。因为Select方法可以接受多个条件的查询以及以一些比较复杂的表达式,处理及解析可能需要耗费一些时间。并且在一般条件下Select是完全搜索,即查找整个集合找到所有满足条件的记录。而Find方法则仅对主键字段进行检索,如果没有设置主键,那么调用Find方法就会报错。 采用Dictionary来代替DataTable结构来进行检索,能达到最快的速度,且几乎不受规模的影响,但是在数据量较大的情况下,将DataTable转换为对应的Dictionary结构可能需要花费时间,如果操作频繁,诸如在进行多个DataTable基于关键字进行拼接的情况下,对目标DataTable使用Dictionary 的方式进行存储,能够使用ContainsKey的基于Hash的方式对关键字进行查找,这能极大地提高效率。并且在DataTable列有重复字段,不能建立主键的情况下,可以采用Dictionary能够解决DataTable无法创建主键,从而导致查找性能下降的问题。
三、实施效果 基于上面的分析,在实际中的工作中,替换了Select方法,创建了一个类型为Dictionary的包含目标合并后DataTable对象的所有行的结构C,其中关键字为SecurityCode,DataRow为包含SecurityCode,High,Low三列数据的行。在合并的时候,直接遍历表A的所有行,然后判断在C中是否包含该行中的SecurityCode,如果包含,取出,直接赋值。然后遍历表B。整个过程使得DataTable合并的效率至少提高了10倍。
四、结语 本文简要介绍了DataTable中检索数据的两种方法,DataTable.Select 和DataTable.Rows.Find方法。在测试方法的执行效率之前介绍了如何为DataTable设置主键,并比较了在数据填充之前和数据填充之后设置主键花费的时间,结果表明,在数据填充完成之后,设置主键要比在填充数据之前设置主键效率要高的多。 设置主键之后,比较了在有无主键的情况下,DataTable.Select 方法在仅对主键字段进行过滤时的性能,结果表明,在仅对主键进行检索时,设置主键之后使用DataTable.Select 方法会比没有主键的情况下的检索速度会快非常多。在相同条件下,如果仅需要查找某一条记录,使用DataTable.Rows.Find会比DataTable.Select快很多。 在某些需要频繁操作DataTable查询的时候,要避免在循环体内调用DataTable.Select方法,采用将DataTable转换为等价的Dictionary结构,能够有效解决由于键值重复导致不能创建主键的问题,并且Dicitonary的采用哈希表的方式查找能够极大地提高查询效率。
|
【本文地址】
今日新闻 |
推荐新闻 |